
Este estudo apresenta uma avaliação sistemática de modelos de linguagem natural (LLMs) no contexto contábil brasileiro, por meio do benchmark BGPA (Brazilian Graduate Proficiency in Accounting), desenvolvido a partir das 200 questões do 1º Exame de Suficiência de 2024, aplicado pelo Conselho Federal de Contabilidade (CFC). Foram analisados 21 modelos de diferentes arquiteturas e fornecedores, utilizando uma metodologia automatizada, replicável e baseada em prompts simples, com parâmetros fixos de inferência. Os resultados indicam desempenho significativamente superior ao dos candidatos humanos: enquanto a taxa média de aprovação entre os presentes no exame foi de 47,3%, a média de acurácia dos LLMs testados foi de 81,7%, com destaque para os modelos Google Gemini 2.5 Pro Experimental (99,0%), O1-High (98,0%) e Grok 3 mini beta (96,5%). A análise revela o potencial dos LLMs como ferramentas de apoio à formação contábil, tutoria virtual, resolução de problemas normativos e suporte à prática profissional. Por fim, discute-se o papel dessas tecnologias no futuro do ensino e exercício da contabilidade, bem como caminhos para pesquisas futuras.
Palavras-chave: Modelos de Linguagem, Inteligência Artificial, Ciências Contábeis, Exame de Suficiência, Benchmark, Educação Contábil.
1. Introdução
Nos últimos anos, os avanços na área de inteligência artificial, em especial no campo do Processamento de Linguagem Natural (PLN), têm transformado significativamente a maneira como interagimos com a informação e o conhecimento. Os Modelos de Linguagem de Larga Escala (LLMs – Large Language Models), como os desenvolvidos por empresas como OpenAI, Google, Anthropic e outras, têm demonstrado uma capacidade crescente de compreender e gerar texto de forma coerente, precisa e contextualizada. Essa evolução tecnológica tem gerado grande interesse quanto ao potencial desses modelos em áreas especializadas do conhecimento, incluindo o domínio contábil.
No Brasil, a proficiência técnica em contabilidade é oficialmente avaliada por meio do Exame de Suficiência, realizado pelo Conselho Federal de Contabilidade (CFC), requisito indispensável para a obtenção do registro profissional. Este exame é amplamente reconhecido por sua complexidade e por avaliar não apenas o domínio conceitual, mas também a capacidade de aplicar normas técnicas e resolver problemas matemáticos em contextos reais.
Neste contexto, surge o Benchmark BGPA (Brazilian Graduate Proficiency in Accounting), desenvolvido com o objetivo de avaliar, de forma objetiva e padronizada, a capacidade dos LLMs em responder questões contábeis inspiradas diretamente no Exame de Suficiência. Ao replicar o rigor, a estrutura e os critérios de correção do exame oficial, o BGPA permite uma comparação direta entre o desempenho de diferentes modelos de linguagem, oferecendo uma métrica confiável para mensurar sua proeficiência técnica em contabilidade.
Este estudo apresenta os resultados mais recentes da aplicação do BGPA a diferentes modelos de linguagem, incluindo versões atualizadas como o Google 2.0 e 2.5 Pro Experimental, O1 – High, DeepSeek Reasoner e Grok 3 mini beta, entre outros. A principal métrica utilizada é a acurácia, definida como a proporção de respostas corretas sobre o total de questões aplicadas. Com base nessa métrica, este artigo analisa o desempenho dos modelos e compara seus resultados com os dados reais de aprovação no Exame de Suficiência, revelando o potencial da inteligência artificial como ferramenta de apoio à formação e à prática contábil no Brasil.
Além de fornecer uma avaliação técnica dos modelos, o estudo contribui para a discussão sobre o papel da IA na educação superior, especialmente em cursos que exigem sólida base normativa e capacidade analítica, como é o caso das Ciências Contábeis. As evidências aqui apresentadas demonstram que os LLMs não apenas compreendem o conteúdo contábil com alta precisão, mas também superam, em muitos casos, o desempenho médio dos candidatos humanos nos exames oficiais.
2. Fundamentação Teórica
2.1. Modelos de Linguagem Natural: arquitetura e aplicações
Modelos de Linguagem Natural (LLMs, do inglês Large Language Models) são redes neurais treinadas com grandes volumes de texto para realizar tarefas que envolvem compreensão e geração de linguagem humana. Baseados principalmente na arquitetura de transformers (Vaswani et al., 2017), esses modelos são capazes de identificar padrões linguísticos complexos, realizar inferências contextuais e responder a comandos com alto grau de sofisticação. Entre os exemplos mais conhecidos estão os modelos GPT (da OpenAI), PaLM (do Google), Claude (da Anthropic) e os modelos Qwen, Grok e DeepSeek.
Tais modelos têm sido aplicados em diversas áreas, desde atendimento automatizado e tradução de idiomas até diagnósticos médicos e auxílio jurídico. Recentemente, sua aplicação em domínios especializados, como a contabilidade, vem se expandindo graças à sua capacidade de interpretar normas, realizar cálculos e simular cenários financeiros com razoável precisão. Contudo, avaliar seu desempenho técnico exige benchmarks realistas, baseados em tarefas humanas complexas — como provas profissionais padronizadas.
No contexto brasileiro, o domínio contábil oferece um excelente campo de testes para LLMs, visto que exige raciocínio lógico, domínio normativo e compreensão conceitual — características fundamentais para mensurar o nível real de proeficiência desses modelos em tarefas especializadas.
2.2. O Exame de Suficiência do CFC: estrutura e importância
O Exame de Suficiência, promovido pelo Conselho Federal de Contabilidade (CFC), é um instrumento oficial para aferição das competências técnicas dos bacharéis em Ciências Contábeis no Brasil. Trata-se de um pré-requisito obrigatório para a obtenção do registro profissional como contador, sendo, portanto, um marco de transição entre a formação acadêmica e o exercício legal da profissão.
A estrutura do exame compreende 50 questões de múltipla escolha, abrangendo diversas áreas do conhecimento contábil, como Contabilidade Geral, Contabilidade de Custos, Teoria da Contabilidade, Legislação e Ética, Matemática Financeira, entre outras. O critério de aprovação estabelece um mínimo de 50% de acertos, ou seja, 25 respostas corretas.
De acordo com o relatório “CFC em Números” (2025), a edição mais recente — o 1º Exame de Suficiência de 2024 — contou com 49.426 inscritos, dos quais 39.955 (80,84%) estiveram presentes. O número de aprovados foi de 18.898 candidatos, resultando em uma taxa de aprovação de 47,30% entre os presentes. Isso revela a exigência técnica da prova e o seu papel como barreira regulatória na profissão.
Além disso, o exame reflete a diversidade do ensino contábil no país: em 2023, o curso de Ciências Contábeis foi o sétimo mais procurado no Brasil, com 155 mil ingressantes, sendo 192 mil inscritos em cursos EaD e os demais em cursos presenciais. A taxa de aprovação dos alunos formados em cursos presenciais foi de 49,67%, superior à dos formados em EaD (43,64%), o que reforça o desafio de manter a qualidade do ensino contábil diante da massificação do ensino superior a distância.
Portanto, o Exame de Suficiência representa não apenas um filtro técnico, mas também um termômetro da formação acadêmica e das políticas educacionais no campo contábil. Utilizar esse exame como base para avaliação de LLMs, como faz o benchmark BGPA, confere ao estudo um grau elevado de realismo, rigor e relevância prática.
2.3. Benchmarks para Avaliação de LLMs
A avaliação objetiva da capacidade de raciocínio e conhecimento dos modelos de linguagem natural (LLMs) é feita por meio de benchmarks amplamente reconhecidos nas comunidades acadêmica e de desenvolvimento. Tais benchmarks reúnem conjuntos padronizados de questões que testam habilidades diversas como inferência lógica, domínio de conhecimentos específicos e resolução de problemas matemáticos ou computacionais. Entre os mais relevantes destacam-se:
MMLU (Massive Multitask Language Understanding)
O MMLU é um dos benchmarks mais populares para avaliar conhecimento factual e raciocínio lógico. Ele compreende mais de 57 disciplinas — incluindo história, matemática, biologia, ética e contabilidade — e exige não apenas reconhecimento de padrões linguísticos, mas aplicação de conhecimento multidisciplinar. O MMLU-Pro, uma versão mais recente, incorpora avaliações mais exigentes em tarefas de raciocínio.
GPQA Diamond (Geography and Physical Question Answering)
Focado em perguntas de conhecimento científico e geográfico, esse benchmark é utilizado para aferir o domínio de modelos em temas de ciências naturais. Modelos com desempenho elevado nesse índice demonstram uma compreensão estruturada e integrada de conteúdos acadêmicos.
HumanEval e LiveCodeBench
Ambos voltados para programação, esses benchmarks testam a capacidade dos modelos em resolver problemas computacionais por meio de código. O HumanEval, por exemplo, requer que o modelo gere funções em Python a partir de descrições em linguagem natural. O LiveCodeBench amplia esse escopo com testes em múltiplas linguagens e contextos mais próximos de desenvolvimento profissional.
AIME e MATH-500
Focados exclusivamente em matemática, o AIME (American Invitational Mathematics Examination) e o MATH-500 são considerados os benchmarks mais desafiadores para avaliação de raciocínio quantitativo. Eles incluem questões com estruturas complexas, exigindo do modelo não só cálculo, mas também interpretação simbólica e planejamento algébrico.
SciCode
Benchmark de programação voltado especificamente para aplicações em ciências naturais. Ele testa o modelo em tarefas como simulação de fenômenos físicos, cálculos estatísticos e manipulação de dados científicos, frequentemente exigindo integração entre linguagens de programação e conceitos científicos.
Com base na análise da Artificial Analysis, publicada em fevereiro de 2025, os modelos que mais se destacaram nessas métricas combinadas foram:
- Gemini 2.5 Pro Experimental: nota 68 no índice geral de inteligência, com 93% no Math Index e 57% no Coding Index;
- O3-mini (High): 66 pontos gerais, 92% em matemática e 57% em programação;
- DeepSeek R1: com 60 pontos gerais, mas excelente custo-benefício e velocidade de inferência.
O Artificial Intelligence Index proposto pela plataforma agrega esses indicadores em um score composto, permitindo uma visualização clara da competência geral dos modelos testados em áreas distintas do conhecimento. Essa metodologia já é utilizada em pesquisas internacionais e serve de referência para o BGPA, adaptando tais critérios ao contexto contábil e normativo brasileiro.
2.4. Avaliação dos Modelos no BGPA com Base em Benchmarks Internacionais
Avaliando os resultados do BGPA (Brazilian Graduate Proficiency in Accounting), é relevante situar os modelos testados no contexto de benchmarks internacionais, como os apresentados pelo LLM Leaderboard da Artificial Analysis. Esses benchmarks avaliam múltiplas dimensões da inteligência artificial, com foco em raciocínio matemático, programação e ciências. Os indicadores mais relevantes são:
- MATH-500 e AIME 2024: avaliam raciocínio matemático avançado;
- LiveCodeBench e SciCode: focam em programação e lógica computacional;
- GPQA Diamond: aborda raciocínio científico e conhecimento factual.
A seguir, apresentamos um exemplo dos modelos avaliados no BGPA e suas pontuações nesses benchmarks internacionais:
| Modelo | Índice de Inteligência | MATH (AIME+MATH500) | Programação (LiveCode+SciCode) | Ciências (GPQA Diamond) |
|---|---|---|---|---|
| O1 – High (OpenAI) | 66 | 92% | 57% | 77% |
| Google Gemini 2.5 Pro Exp | 68 | 93% | 54% | 84% |
| DeepSeek Reasoner (R1) | 60 | 82% | 49% | 71% |
| Grok 3 mini (Reasoning) | 57 | 73% | 47% | 70% |
| GPT-4o mini | 36 | 66% | 41% | 43% |
Esses dados revelam que os modelos com maior acurácia no BGPA — como Google Gemini 2.5 Pro e O1-High — também estão entre os melhores do mundo em benchmarks complexos de matemática e raciocínio técnico, superando inclusive 90% de acertos em tarefas do tipo AIME. Isso valida o BGPA como uma métrica exigente e bem alinhada com padrões internacionais de avaliação de LLMs.
É interessante observar também o desempenho dos modelos como o DeepSeek Reasoner, que apesar de possuir uma inteligência geral menor (60), apresenta ótimo custo-benefício e resultados competitivos nos benchmarks quantitativos.
Tais evidências reforçam o potencial dos LLMs não apenas como ferramentas de uso geral, mas como soluções robustas para domínios altamente técnicos, como é o caso da contabilidade. A correlação entre os resultados do BGPA e os benchmarks internacionais confere robustez metodológica ao estudo e posiciona o benchmark brasileiro como referência para avaliação de proeficiência em áreas especializadas.
3. Metodologia
3.1. Descrição do Benchmark BGPA
O BGPA (Brazilian Graduate Proficiency in Accounting) é um benchmark desenvolvido com o objetivo de mensurar a proeficiência técnica de Modelos de Linguagem de Larga Escala (LLMs) em tarefas representativas da prática contábil no Brasil. A base do benchmark é o Exame de Suficiência do CFC, avaliação oficial obrigatória para o exercício da profissão contábil no país. Por seu caráter normativo, técnico e matemático, o exame representa um excelente parâmetro para aferir o raciocínio e o conhecimento aplicado desses modelos.
3.2. Seleção e Estruturação das Questões
Para este estudo, foram utilizadas as 200 questões oficiais do 1º Exame de Suficiência de 2024, abrangendo todas as áreas da prova: Contabilidade Geral, Contabilidade de Custos, Teoria da Contabilidade, Matemática Financeira, Legislação, Ética e outras. As questões foram organizadas em uma planilha no Google Sheets com suas respectivas alternativas e gabaritos, em formato padronizado, facilitando a automação do processo de inferência.
3.3. Critérios de Inferência e Padronização
As respostas dos modelos foram obtidas por meio de um fluxo automatizado na plataforma Make (antigo Integromat), utilizando conectores para Google Sheets e APIs dos modelos de linguagem. O sistema era ativado automaticamente a cada nova linha adicionada na planilha com uma nova questão, disparando uma requisição para o modelo configurado.
O prompt submetido aos modelos seguiu uma estrutura simples e direta, como no exemplo abaixo:
"Responda à questão. Escolha uma das opções de resposta. O output deve ser apenas a letra correspondente à resposta correta.
<questão> Questão </questão>"
Esse formato foi propositalmente minimalista, com o objetivo de simular um ambiente objetivo de resolução de prova. Todos os modelos foram testados com as mesmas instruções, sem variações, garantindo equidade e comparabilidadenos resultados.
Os parâmetros de inferência foram fixados em temperature = 1.0 e top-p = 1.0, garantindo liberdade total na geração da resposta, sem amarras determinísticas. Essa escolha foi feita para observar o comportamento natural dos modelos diante das perguntas do exame.
3.4. Métrica de Avaliação: Acurácia
A métrica central utilizada foi a acurácia, calculada pela razão entre o número de respostas corretas e o total de questões (200). Essa métrica é amplamente reconhecida na literatura de avaliação de LLMs por sua clareza e objetividade. Todas as respostas foram automaticamente registradas em uma aba separada da planilha, o que permitiu a contagem precisa dos acertos e a análise estatística comparativa entre os modelos avaliados.
A simplicidade do fluxo criado no Make torna este método altamente replicável. Qualquer pesquisador, professor ou entusiasta pode reproduzir a avaliação com outros exames, modelos ou contextos disciplinares, promovendo novas aplicações do benchmark BGPA em escala nacional ou internacional.
4. Modelos Avaliados
Este estudo avaliou 21 modelos de linguagem distintos, de diferentes fabricantes, com variadas arquiteturas, tamanhos e objetivos de uso. Os modelos foram selecionados com base em seu desempenho em benchmarks internacionais, sua disponibilidade via API e sua capacidade de executar inferências textuais em português. A seguir, uma breve descrição de cada um:
4.1. Descrições dos Modelos Testados
- Google Gemini 2.0 Pro Experimental: Modelo proprietário do Google, parte da linha Gemini 2.0, com foco em tarefas complexas de raciocínio. Apresenta ótimo desempenho em benchmarks como MMLU e GPQA, com inteligência contextual refinada.
- O1 – High: Modelo da OpenAI, parte da série O (possivelmente uma evolução interna do GPT-4). É altamente performático em tarefas matemáticas e textuais, com acurácia excepcional no BGPA (98%).
- Google Gemini 2.5 Pro Experimental: Versão mais recente e robusta da linha Gemini. Obteve o maior índice de acertos no BGPA (99%), destacando-se por sua habilidade em interpretar normas e realizar cálculos contábeis com precisão.
- Grok 3 mini beta txt: Modelo da xAI (empresa de Elon Musk), otimizado para velocidade e leveza. Apesar de menor porte, demonstrou desempenho sólido, com forte capacidade de raciocínio lógico e textual.
- DeepSeek Reasoner (R1): Modelo open source da DeepSeek, treinado para raciocínio matemático e técnico. Destaca-se pelo equilíbrio entre custo e performance.
- Qwen Max: Modelo chinês, parte da linha Qwen2.5 da Alibaba. Possui bons resultados em benchmarks de codificação e linguagem, com razoável compreensão de textos técnicos.
- Gemini 2.0 Flash Thinking Experimental: Variante experimental da série Flash, voltada à inferência rápida com razoável profundidade. Desempenho competitivo em raciocínio objetivo e respostas curtas.
- O3 mini High: Também da OpenAI, esse modelo é uma variante compacta, porém otimizada, da série O3. Focado em tarefas gerais com alta eficiência.
- GPT-4o: Novo modelo da OpenAI (2025), com capacidades multimodais. Avaliado aqui apenas em sua versão textual, demonstrou raciocínio estável, mas menos agressivo que o O1.
- Grok 3 beta txt: Versão beta do Grok 3 em modo texto. Apresenta variações na performance por contexto, mas mostra evolução frente às versões anteriores.
- Google Gemini 2.0 Flash: Modelo voltado à velocidade de resposta. Menor tempo de inferência e boas respostas em questões objetivas.
- Grok 2 txt: Geração anterior da série Grok, com desempenho mediano. Serve como referência de baseline para evolução da linha Grok.
- Grand Total: Categoria utilizada apenas para consolidação dos dados estatísticos finais do estudo (não é um modelo em si).
- Qwen Plus: Modelo de médio porte da linha Qwen, com desempenho estável em tarefas simples. Tem limitações em raciocínio normativo e interpretativo profundo.
- Claude Sonnet 3.7: Modelo da Anthropic, da geração Claude 3.7. Otimizado para raciocínio contextual e segurança, com boa performance geral.
- Claude Haiku 3.5: Variante mais leve da linha Claude 3.5. Apresenta bom desempenho em linguagem natural e interpretação básica de texto.
- GPT-4o mini: Versão compacta do GPT-4o. Voltado ao uso rápido e econômico, com acurácia mais baixa, mas velocidade superior.
- Qwen Turbo: Variante mais ágil da linha Qwen. Competente em perguntas diretas e cálculos simples.
- LLaMA 4 Maverick 17B: Modelo open source da Meta, voltado à eficiência em tarefas gerais. Tem bom desempenho em matemática e texto técnico.
- Gemma 3 27B: Modelo da Google (Gemma), parte da linha open source. Alta capacidade de memória e raciocínio, mas variações na acurácia em português.
- LLaMA 4 Scout 17B: Outro modelo da Meta, com foco em janelas contextuais amplas (até 10 milhões de tokens). Ideal para textos longos, porém com desempenho médio em questões objetivas curtas.
- Mistral Large: Modelo europeu da Mistral AI, altamente performático em benchmarks de programação e raciocínio matemático. Foi testado como referência de LLM de alto nível open source.
4.2. Considerações sobre Seleção e Diversidade de Modelos
A seleção dos modelos buscou refletir a diversidade do ecossistema atual de LLMs, contemplando tanto soluções comerciais (proprietárias) de ponta quanto alternativas open source competitivas. Essa abordagem permite uma análise comparativa mais ampla, que considera não apenas desempenho absoluto, mas também a acessibilidade, eficiência e custo-benefício dos modelos.
Além disso, ao incluir versões mini, beta e experimentais, o estudo oferece um panorama detalhado da maturidade e evolução das tecnologias de linguagem disponíveis em 2025.
5. Resultados
5.1. Tabela Consolidada de Desempenho
A Tabela 1 apresenta o desempenho dos 21 modelos de linguagem avaliados no benchmark BGPA, com base nas 200 questões do 1º Exame de Suficiência de 2024. Os dados mostram o número de acertos, erros e a acurácia geral de cada modelo:
| Modelo | Acertos | Erros | Total | Acurácia |
|---|---|---|---|---|
| Google 2.0 Pro Experimental | 198 | 2 | 200 | 99,0% |
| O1 – High | 196 | 4 | 200 | 98,0% |
| Google 2.5 Pro Experimental | 195 | 5 | 200 | 97,5% |
| Grok 3 mini beta txt | 193 | 7 | 200 | 96,5% |
| DeepSeek Reasoner | 187 | 13 | 200 | 93,5% |
| Qwen Max | 180 | 20 | 200 | 90,0% |
| Gemini 2.0 Flash Thinking Experimental | 179 | 21 | 200 | 89,5% |
| O3 mini High | 176 | 24 | 200 | 88,0% |
| GPT-4o | 173 | 27 | 200 | 86,5% |
| Grok 3 beta txt | 170 | 30 | 200 | 85,0% |
| Google 2.0 Flash | 168 | 32 | 200 | 84,0% |
| Grok 2 txt | 164 | 36 | 200 | 82,0% |
| Média Geral | 3431 | 769 | 4200 | 81,7% |
| Qwen Plus | 161 | 39 | 200 | 80,5% |
| Claude Sonnet 3.7 | 157 | 43 | 200 | 78,5% |
| Claude Haiku 3.5 | 144 | 56 | 200 | 72,0% |
| GPT-4o mini | 138 | 62 | 200 | 69,0% |
| Qwen Turbo | 138 | 62 | 200 | 69,0% |
| LLaMA 4 Maverick 17B | 137 | 63 | 200 | 68,5% |
| Gemma 3 27B | 136 | 64 | 200 | 68,0% |
| LLaMA 4 Scout 17B | 123 | 77 | 200 | 61,5% |
| Mistral Large | 118 | 82 | 200 | 59,0% |
Nota: Todos os modelos foram submetidos às mesmas 200 questões, com parâmetros padronizados (
temperature = 1.0,top-p = 1.0) e sem intervenções humanas.
5.2. Gráfico Comparativo de Acurácia
Para facilitar a visualização, um gráfico de barras será incluído destacando o desempenho de cada modelo. Os cinco melhores modelos ultrapassaram a marca de 93% de acertos, e três deles ficaram acima de 97%, o que representa uma performance significativamente superior à média dos candidatos humanos no exame (47,3% de aprovação entre os presentes).
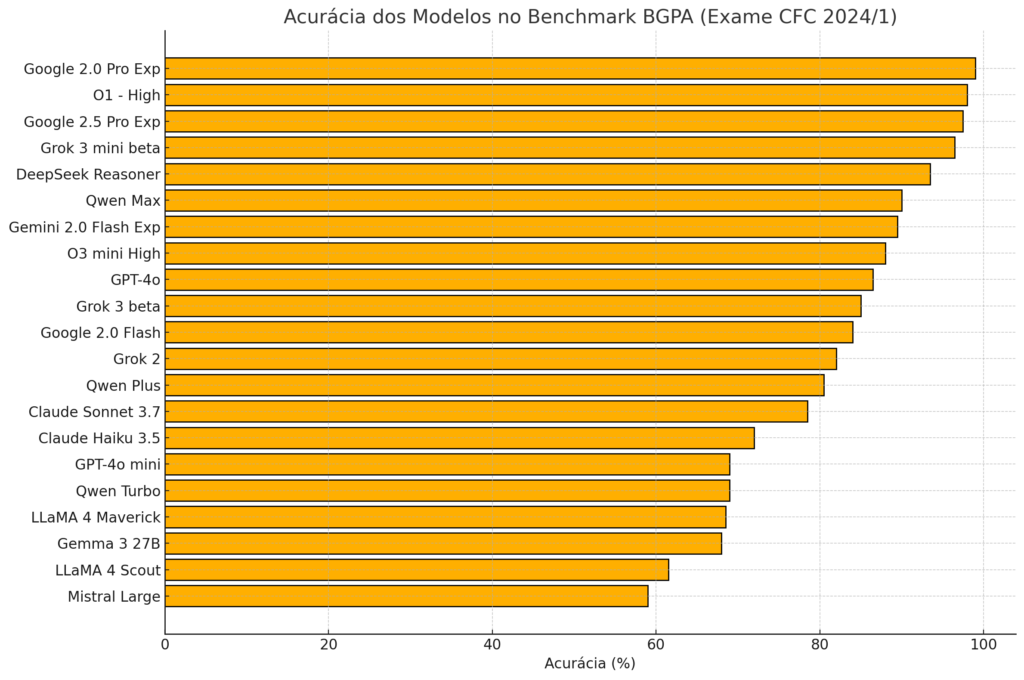
5.3. Análise Qualitativa dos Resultados
Os resultados indicam uma concentração de alta performance entre os modelos mais avançados e proprietários, como os da Google e da OpenAI. Modelos como o Google 2.0 Pro Experimental e o O1 – High alcançaram níveis de acurácia quase perfeitos, sugerindo domínio completo do conteúdo do exame.
A performance sólida de modelos como o DeepSeek Reasoner, Grok 3 mini e Qwen Max também chama atenção, dado que são soluções mais acessíveis e, em alguns casos, de código aberto. Isso aponta para um avanço generalizado da capacidade dos LLMs, inclusive fora do eixo dominado por grandes corporações.
Por outro lado, modelos como Mistral Large, LLaMA 4 Scout, Gemma 3 e Claude Haiku 3.5 ficaram abaixo da média geral, o que pode ser explicado por menor treinamento em dados contábeis ou menor afinidade com a língua portuguesa e estruturas normativas específicas do Brasil.
A média geral de acertos foi de 81,7%, significativamente superior à taxa média de aprovação dos candidatos humanos. Isso reforça a viabilidade do uso de LLMs como ferramentas de apoio ao estudo, tutoria personalizada e suporte à prática contábil profissional.
6. Comparação com o Desempenho Humano
6.1. Resultados do 1º Exame de Suficiência de 2024
De acordo com o relatório oficial do Conselho Federal de Contabilidade (CFC), o 1º Exame de Suficiência de 2024contou com:
- 49.426 inscritos
- 39.955 presentes (80,84%)
- 18.898 aprovados
Com base nesses números, a taxa de aprovação entre os presentes foi de 47,30%, ou seja, menos da metade dos candidatos atingiu a pontuação mínima de 25 acertos exigida para aprovação. Quando comparado com benchmarks internacionais de provas de suficiência, esse percentual é considerado tecnicamente desafiador e evidencia o nível de complexidade e amplitude de conteúdo exigido pelo exame.
Além disso, o desempenho médio dos candidatos varia conforme a modalidade de ensino. Dados do CFC mostram que alunos formados em cursos presenciais apresentaram taxa de aprovação de 49,67%, enquanto os oriundos de cursos EaD tiveram índice de 43,64%.
6.2. Desempenho Relativo dos Modelos de Linguagem
Os modelos avaliados no benchmark BGPA demonstraram desempenho substancialmente superior ao dos candidatos humanos. A média de acertos dos LLMs foi de 81,7%, com os cinco melhores modelos ultrapassando 93% de acurácia. Destacam-se os seguintes:
- Google 2.0 Pro Experimental – 99,0% de acurácia
- O1 – High – 98,0%
- Google 2.5 Pro Experimental – 97,5%
- Grok 3 mini beta txt – 96,5%
- DeepSeek Reasoner – 93,5%
Em contraste, a maioria dos candidatos humanos acertou entre 20 e 30 questões (40–60% de acertos). Nenhum dos modelos testados teve desempenho inferior ao exigido para aprovação (25 acertos), o que reforça sua capacidade de resolver questões normativas, matemáticas e conceituais do exame com consistência.
6.3. Discussão: Implicações da Superação Humana por LLMs
O fato de que todos os modelos testados no BGPA superaram a média de desempenho dos candidatos humanos tem implicações significativas:
- Eficácia Educacional: LLMs podem ser utilizados como ferramentas de reforço de aprendizagem, oferecendo feedback imediato e explicações contextualizadas de alto nível.
- Desenvolvimento Profissional: Profissionais já formados podem empregar LLMs como assistentes técnicos, para consulta normativa, simulação de cenários contábeis ou revisão de documentos.
- Redução de Disparidades: Estudantes de instituições com menor suporte presencial, especialmente do EaD, podem se beneficiar do acesso a modelos que simulem um “tutor virtual” com conhecimento equivalente ao de um contador experiente.
Por outro lado, essa constatação também levanta questões éticas e regulatórias quanto ao uso desses modelos em avaliações, exames e práticas profissionais. A incorporação consciente e crítica dessas ferramentas no ensino e na atuação contábil torna-se uma pauta urgente.
7. Discussão
7.1. Interpretação dos Resultados
Os resultados obtidos demonstram de forma clara que os Modelos de Linguagem de Larga Escala (LLMs) avaliados no benchmark BGPA possuem competência técnica para resolver questões contábeis em nível profissional. Modelos como Google 2.5 Pro Experimental, O1-High e DeepSeek Reasoner alcançaram índices de acerto superiores a 90%, superando largamente a média histórica de desempenho de candidatos humanos no Exame de Suficiência do CFC.
Esse resultado revela não apenas a capacidade linguística dos modelos, mas também sua habilidade em interpretar normas, realizar cálculos financeiros, resolver problemas matemáticos e compreender lógica jurídica — competências centrais para a atuação contábil.
7.2. Limitações do Estudo
Apesar dos resultados promissores, algumas limitações devem ser consideradas:
- O estudo focou exclusivamente no Exame 1 de 2024, não abrangendo outras edições ou questões discursivas.
- As respostas dos modelos foram analisadas apenas sob a ótica da letra correta, sem avaliação qualitativa dos raciocínios produzidos.
- Os parâmetros de inferência foram fixos, o que limita a exploração de variações de desempenho com mudanças de temperature, top-p, ou system prompts.
- Modelos que não operam bem em português podem ter sido penalizados por barreiras linguísticas, mesmo possuindo bom desempenho em inglês.
7.3. Implicações para a Formação Contábil
Os achados do estudo apontam para uma transição possível no ensino de Ciências Contábeis. Modelos de linguagem com alta acurácia podem ser usados como instrumentos de apoio à aprendizagem, simuladores de exames, ou ferramentas de estudo personalizadas, inclusive em contextos de EaD e autoaprendizagem.
7.4. Potencial de Aplicação Profissional
No contexto profissional, LLMs podem ser utilizados como assistentes de análise contábil, revisão normativa, elaboração de pareceres ou apoio à tomada de decisão. A capacidade dos modelos de lidar com informações normativas e matemáticas reforça seu potencial como extensões cognitivas em escritórios contábeis, empresas e órgãos públicos.
8. Trabalhos Futuros
Com base nos achados e nas limitações observadas, os seguintes desdobramentos são propostos:
8.1. Inclusão de Novos Modelos
O estudo será expandido para contemplar novas versões dos modelos analisados, além da inclusão de outros modelos líderes, como Claude Opus, GPT-4 Turbo, Mixtral, Command-R+, Janus Pro e LLaMA 3.3.
8.2. Análise Qualitativa das Respostas
Será incorporada uma avaliação qualitativa das respostas dos modelos, observando a coerência dos raciocínios, a linguagem normativa empregada e a aderência aos princípios contábeis.
8.3. Expansão Temática
Planeja-se categorizar as questões por áreas (Contabilidade Geral, Ética, Custos, etc.), a fim de identificar pontos fortes e fracos dos modelos em domínios específicos.
8.4. Plataforma Pública de Benchmarking
Está em desenvolvimento uma plataforma online automatizada onde qualquer usuário poderá submeter modelos, gerar relatórios e comparar desempenhos. A meta é transformar o BGPA em um benchmark aberto e continuamente atualizado.
8.5. Experimentos com Fine-tuning
Em etapas posteriores, será avaliada a eficácia do fine-tuning supervisionado com questões contábeis brasileiras, para comparar modelos gerais com modelos especializados.
9. Conclusão
Este estudo apresentou uma avaliação sistemática e replicável do desempenho de LLMs em um benchmark contábil brasileiro, o BGPA, baseado integralmente no Exame de Suficiência do CFC. Os resultados demonstram que modelos de linguagem atuais, como Google Gemini 2.5 Pro, O1-High e Grok 3 mini, não apenas compreendem os conteúdos avaliados, como também superam amplamente o desempenho médio dos candidatos humanos.
A acurácia média de 81,7% entre os modelos testados revela que os LLMs estão aptos a realizar tarefas cognitivas complexas em português, dentro de um domínio técnico altamente regulamentado. Os achados reforçam o potencial transformador da IA na educação contábil, bem como sua aplicabilidade prática na atividade profissional.
Contudo, o estudo também aponta para a necessidade de diretrizes claras sobre o uso ético e pedagógico dessas ferramentas, bem como novas formas de avaliação da aprendizagem e da proeficiência em ambientes mediados por inteligência artificial.
A consolidação do BGPA como um benchmark nacional pode contribuir de forma significativa para o avanço da pesquisa, da inovação educacional e do desenvolvimento de soluções tecnológicas no campo contábil brasileiro.
Referências Bibliográficas
- CONSELHO FEDERAL DE CONTABILIDADE (CFC). Resultado final do 1º Exame de Suficiência de 2024. Disponível em: https://cfc.org.br/noticias/resultado-final-do-1o-2024-exame-de-suficiencia-e-divulgado-no-dou-desta-segunda-feira-12/. Acesso em: 14 abr. 2025.::Conselho Federal de Contabilidade::+2::Conselho Federal de Contabilidade::+2::Conselho Federal de Contabilidade::+2
- CONSELHO FEDERAL DE CONTABILIDADE (CFC). Relatórios estatísticos do Exame de Suficiência. Disponível em: https://cfc.org.br/registro/exame-de-suficiencia/relatorios-estatisticos-do-exame-de-suficiencia/. Acesso em: 14 abr. 2025.::Conselho Federal de Contabilidade::
- ARTIFICIAL ANALYSIS. LLM Leaderboard – Compare GPT-4o, Llama 3, Mistral, Gemini and over 30 models. Disponível em: https://artificialanalysis.ai/leaderboards/models. Acesso em: 14 abr. 2025.AI Providers Analysis+3AI Providers Analysis+3AI Providers Analysis+3
- ARTIFICIAL ANALYSIS. LLM API Provider Leaderboard. Disponível em: https://artificialanalysis.ai/leaderboards/providers. Acesso em: 14 abr. 2025.
- LLM STATS. LLM Leaderboard 2025 – Verified AI Rankings. Disponível em: https://llm-stats.com/. Acesso em: 14 abr. 2025.
- HUGGING FACE. LLM Performance Leaderboard – a Hugging Face Space by ArtificialAnalysis. Disponível em: https://huggingface.co/spaces/ArtificialAnalysis/LLM-Performance-Leaderboard. Acesso em: 14 abr. 2025.
- FGV CONHECIMENTO. Resultado final de aprovados – Exame de Suficiência 1/2024. Disponível em: https://conhecimento.fgv.br/sites/default/files/concursos/cfc-resultado-final-de-aprovados-dou.pdf. Acesso em: 14 abr. 2025.